 [C/C++] 포인터의 포인터(더블 포인터)의 이해
[C/C++] 포인터의 포인터(더블 포인터)의 이해
더블 포인터의 이해 더블 포인터도 싱글 포인터와 마찬가지로 메모리 공간의 주소를 저장하는 변수입니다. 다만, 차이가 나는 것은 포인터가 가르키는 대상입니다. 1 2 3 4 5 6 7 8 int main() { int num = 10; //int형 변수 num에 10 할당 int *pointer_num = # //싱글 포인터 선언 및 num의 주소 값 할당 int **double_pointer = &pointer_num; //더블 포인터 선언 및 pointer_num의 주소 할당 printf("%d \n",**double_pointer); //더블 포인터를 통한 num 값 접근 } 결론부터 말하면 더블 포인터는 싱글 포인터의 주소 값을 저장하기 위한 포인터라는 것입니다. 위의 코드 3번 라인에서 i..
 [C/C++] 포인터와 함수에 대한 이해
[C/C++] 포인터와 함수에 대한 이해
함수의 인자로 배열 전달하기 함수의 인자로 배열을 전달하는 방법에 대해서 살펴 보겠습니다. ■ 1. 함수의 인자 전달 방식 함수에서 인자 전달의 기본 방식은 값의 복사에 의한 전달 방식입니다. 함수 호출에서 값의 복사에 의하 인자 전달 방식입니다. 메인 함수에서 num을 인자로 하여 call_Method 함수를 호출 하고 있고 call_Method 함수에서는 같은 이름의 num을 매개변수로 하여 값을 받고 있습니다. 여기서 '복사'의 의미는 단순히 '10'이라고 하는 값이 복사 된 것입니다. 즉 메인 영역의 num변수와 call_Method 함수의 num은 서로 다른 변수이며 어느 한 영역에서 값이 변경 되도 다른 영역의 num 변수에는 영향을 주지 않습니다. 문제는 배열을 통째로 복사하여 인자로 넘겨주..
 [C/C++] 문자열 상수 포인터
[C/C++] 문자열 상수 포인터
■ 문자열 표현 방식의 이해 문자열을 표현하는 방식에는 크게 두 가지 방식이 있습니다. 하나는 변수로 표현하는 빙식이고, 또 다른 하나는 상수로 표현하는 방식입니다. 1 2 3 4 5 int main() { char str[6] = "Hello"; // 변수를 활용한 문자열 변수 표현 char *str2 = "Hello"; // 포인터를 활용한 문자열 상수 표현 } 첫 번째는 char형인 str이라는 이름의 배열을 선언하고, 대입 연산자 오른쪽에 선언된 문자열을 할당하고 있습니다. 따라서 str이 저장하고 있는 문자열은 변수가 됩니다. 두 번째 str2는 char형 포인터를 선언하고, 오른쪽에는 "Hello"라는 문자열을 선언합니다. 이는 포인터 str2를 이용해서 문자열 상수 "Hello"를 가리키겠다..
 [C/C++] 포인터와 배열
[C/C++] 포인터와 배열
■ 배열의 이름 1 2 3 4 5 6 7 8 9 10 int main() { int num[5] = { 1,2,3,4,5 }; printf("%d\n", num); //배열의 이름 출력 printf("%d, %d\n", &num[0],&num[1]); //배열의 첫 번째 요소와 두 번째 요소 주소 출력 return 0; } int형 배열 num을 선언하고 첫 번째 줄에서 배열의 이름을 출력하고 두 번째 줄에서 배열의 첫 번째 요소와 두 번째 요소의 주소 값을 출력하고 있습니다. 결과를 살펴 보겠습니다. 배열의 첫 번째 요소는 13630876 이고 두 번째 요소는 13630880 입니다. 이는 int형 배열이므로 한 개의 배열 요소가 4바이트의 메모리를 차지한다는 것을 의미합니다. 중요한것은 배열의 이름 ..
포인터 포인터란 메모리의 주소 값을 저장하기 위한 변수로, 기본 자료형 변수와는 달리 메모리 공간의 주소 값을 저장하는데 사용되는 변수를 의미하는 것입니다. 포인터가 변수라는 것을 강조하기 위해 '포인터 변수'라는 표현을 많이 사용합니다. ■포인터 선언하기 123456main (void){ int *a; //a라는 이름의 int형 포인터 char *ch; //ch라는 이름의 char형 포인터 double *d; //d라는 이름의 double형 포인터} 포인터를 선언 할 때는 변수명 앞에 *연산자를 사용함으로써 선언이 가능합니다. ● int *a : int형 변수의 주소 값을 가질 수 있는 int형 포인터 ● char *ch : char형 변수의 주소 값을 가질 수 있는 char형 포인터● double *..
 11 컴포지트 패턴 (Composite Pattern)
11 컴포지트 패턴 (Composite Pattern)
컴포지트 패턴 (Composite Pattern) 객체들을 트리 구조로 구성하여 그릇 객체와 내용물 객체를 동일하게 취급할 수 있도록 만들기 위한 패턴입니다. Composite Pattern Structure ● Component : Leaf와 Composite의 상위 클래스로써 이들을 동일하게 취급 할 수 있도록 공통 인터페이스 정의 ● Composite : 그릇을 나타내는 역할을 하고, 또 다른 그릇을 참조하거나 내용물 객체를 참조 할 수 있음 ● Leaf : 내용물 객체로서, 그릇 객체를 포함 할 수 없음 예제 예제는 디렉토리 구조를 구성하는 예제로 디렉토리는 그릇 객체에 해당되며 파일은 내용물 객체에 해당합니다. 예제의 클래스 다이어그램입니다. Entry 객체는 File과 Directory를 동일..
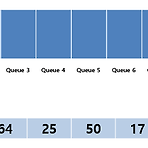 06 정렬 알고리즘 - 기수 정렬(Radix Sort)
06 정렬 알고리즘 - 기수 정렬(Radix Sort)
기수정렬 (Radix Sort) 기수정렬은 낮은 자리수부터 비교하여 정렬해 간다는 것을 기본 개념으로 하는 정렬 알고리즘입니다. 기수정렬은 비교 연산을 하지 않으며 정렬 속도가 빠르지만 데이터 전체 크기에 기수 테이블의 크기만한 메모리가 더 필요합니다. ■ 정렬 방식 1. 0~9 까지의 Bucket(Queue 자료구조의)을 준비한다. 2. 모든 데이터에 대하여 가장 낮은 자리수에 해당하는 Bucket에 차례대로 데이터를 둔다. 3. 0부터 차례대로 버킷에서 데이터를 다시 가져온다. 4. 가장 높은 자리수를 기준으로 하여 자리수를 높여가며 2번 3번 과정을 반복한다. 아래의 8개 데이터에 대하여 기수 정렬을 시도해 보겠습니다. 위의 그림과 같이 각 숫자에 해당하는 Queue공간을 할당하고 진행합니다. 먼저..
 02 선형 큐 (Linear Queue) 자료구조
02 선형 큐 (Linear Queue) 자료구조
선형 큐 (Linear Queue) 큐는 가장 먼저 들어온 데이터가 가장 먼저 내보내지는 (FIFO : First In First Out) 구조를 가집니다. 선형 큐는 데이터를 집어넣는 Enqueue 기능과 데이터를 내보내는 Dequeue 기능을 제공합니다. ■Enqueue 기능 Enqueue는 큐 자료구조에 데이터를 집어 넣는 기능을 수행합니다. 영화 매표소에 사람들이 줄을 선다고 생각해봅니다. 이때 매표소 가장 앞사람을 가르키는 것을 front라 하고 마지막에 서있는 사람을 가르키는 것을 rear이라고 부릅니다. 1번이 Enqueue 되어진 상태입니다. 첫 번째로 줄을 선 사람이므로 front와 rear이 둘다 1번을 가르키고 있습니다. 다음으로 2번이 Enqueue 기능을 수행 한 상태입니다. Fr..
 01 스택 (Stack) 자료 구조
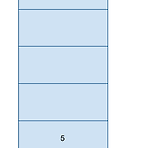
01 스택 (Stack) 자료 구조
스택 (Stack) 스택(Stack)은 한 쪽 끝에서만 자료를 넣거나 뺄 수 있는 선형 구조(LIFO- Last In First Out)으로 되어있습니다. 자료를 넣는 것을 PUSH라고 하고 넣어둔 자료를 꺼내는 것을 POP이라고 합니다. ■ 스택 입/출력 방식 실제로 스택이 어떤 식으로 자료가 입/출력 되는지 살펴 보겠습니다. 상자안에 책을 쌓는다고 생각을 하면 됩니다. 즉 가장 먼저 넣은 책은 가장 나중에 꺼낼 수 있으며, 가장 최근에 넣은 책을 가장 먼저 뺄수 있습니다. 가장 먼저 5를 PUSH 합니다. 스택 자료 구조에 가장 아래에 위치하게 됩니다. 차례대로 PUSH 4, PUSH 3을 한 결과입니다. POP 2회를 실시하게 되면 출력 결과는 3,4가 됩니다. 즉 3은 가장 나중에 입력 되었지만 ..
 10 역할 사슬 패턴 (Chain Of Responsibility)
10 역할 사슬 패턴 (Chain Of Responsibility)
역할 사슬 패턴 (Chain Of Responsibility) 여러 개의 객체 중에서 어떤 것이 요구를 처리할 수 있는지를 사전에 알 수 없을 때 사용됩니다. 즉 요청 처리가 들어오게 되면 그것을 수신하는 객체가 자신이 처리 할 수 없는 경우에는 다음 객체에게 문제를 넘김으로써 최종적으로 요청을 처리 할 수 있는 객체의 의해 처리가 가능하도록 하는 패턴입니다. 구조 (Structure) ● Handler : 요청을 처리하기 위한 수신자들이 가져야 할 인터페이스를 정의 ● ConcreteHandler : Handler 인터페이스 구현, 각자가 요청 종류에 따라 자신이 처리 할 수 있는 부분을 구현 ● Client : 맨 처음 수신자에게 처리를 요구함 예제 예제는 역할 사슬 패턴을 사용하여 1~20까지의 반..
 [JAVA] 쓰레드 (Thread) 사용하기
[JAVA] 쓰레드 (Thread) 사용하기
쓰레드 (Thread) 실행 중인 프로그램을 프로세스(Process)라고 부릅니다. 한 개의 프로세스는 한가지 일을 수행하지만 Thread를 사용하게 되면 한 프로세스 내에서 여러가지 작업을 동시에 수행 할 수 있게 됩니다. ■ 기본적인 쓰레드 사용 Thread를 상속받아 run() 메소드를 오버라이딩을 함으로써 간단한 Thread을 구현 해보겠습니다. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 public class Thread1 extends Thread{ int index ; public Thread1(int index) { this.index = index; } public void run() /..
 11 [객체 지향 언어의 이해] 업캐스팅과 다운캐스팅
11 [객체 지향 언어의 이해] 업캐스팅과 다운캐스팅
업캐스팅 (UPCASTING) 상위 클래스의 객체 참조 변수에 하위 클래스의 인스턴스를 대입하는 것을 의미합니다. 모든 객체 내의 모든 멤버에 접근 할 수 없고, 상위 클래스의 멤버에만 접근이 가능합니다. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 public class Main { public static void main(String argsp[]) { Top top = new Top(); //상위 클래스 타입에 상위 클래스 인스턴스 대입 top.show(); top = new Bottom(); //상위 클래스 타입에 하위 클래스 인스턴스 대입 top.show(); } } public cl..
 09 퍼사드 패턴 (Facade Pattern)
09 퍼사드 패턴 (Facade Pattern)
퍼사드 패턴 (Facade Pattern) Facade는 "건물의 정면"을 의미하는 단어로 어떤 소프트웨어의 다른 커다란 코드 부분에 대하여 간략화된 인터페이스를 제공해주는 디자인 패턴을 의미합니다. 퍼사드 객체는 복잡한 소프트웨어 바깥쪽의 코드가 라이브러리의 안쪽 코드에 의존하는 일을 감소시켜 주고, 복잡한 소프트웨어를 사용 할 수 있게 간단한 인터페이스를 제공해줍니다. 동기 어떤 사람이 영화를 보고자 합니다. 영화를 보기 위해서는 다음과 같은 과정을 거치게 됩니다. 음료를 준비한다 -> TV를 켠다 -> 영화를 검색한다 -> 영화를 결제한다 -> 영화를 재생한다. 123456789101112public void view(){ Beverage beverage = new Beverage("콜라"); Re..
 05 정렬 알고리즘 - 병합 정렬 (Merge Sort)
05 정렬 알고리즘 - 병합 정렬 (Merge Sort)
병합 정렬 (Merge Sort) 전체 원소를 하나의 단위로 분할한 후에 분할한 원소를 다시 병합하며 정렬해 나가는 방식입니다. ■ 정렬 방식 1. 정렬하고자 하는 데이터 집합을 반으로 나눈다. 2. 반으로 나누어진 하위 데이터의 개수가 2이상이면 1의 과정을 반복한다. 3. 같은 집합에서 나온 하위 데이터 둘을 정렬을 시도하면서 다시 병합합니다. 4. 원래의 데이터 집합이 될때까지 3의 과정을 반복합니다. - 분할과정 전체 데이터 크기(n=8)에서 반으로(n=4) 나눕니다. 이 과정에 대해서 데이터 집합의 크기가 1이 될 때까지 반복합니다. -병합과정 같은 집합에서 나온 하위 데이터집합 두개를 정렬과 동시에 병합을 시도합니다. 주목해야 할 점은 병합이 이루어진 데이터 집합에 대해서는 정렬이 이루어졌습니..
 08 반복자 패턴 (Iterator Pattern)
08 반복자 패턴 (Iterator Pattern)
반복자 패턴 (Iterator Pattern) 접근기능과 자료구조를 분리시켜서 객체화합니다. 서로 다른 구조를 가지고 있는 저장 객체에 대해서 접근하기 위해서 interface를 통일시키고 싶을 때 사용하는 패턴입니다. 동기 for(int i=0;i ™ 1 2 3 4 5 6 7 8 public interface Aggregate { public abstract Iterator iterator(); } public interface Iterator { public abstract boolean hasNext(); public abstract Object next(); } Aggregate의 인터페이스를 구현하는 복합 클래스는 반드시 iterator 객체를 생성하는 메서드를 구현합니다. Iterator 인터..